Usually, big data applications are one of two types: data at rest and data in motion. The difference between them is the same as the difference between a lake and a river—a lake is a place that contains a lot of water while a river is a place where a lot of water is travelling through.
For this reason, data at rest applications are often referred to as a data lake while data in motion applications are called data streams or data rivers.
Fun Fact
The “Rio de la plata”, located next to our office in Uruguay, is the widest river in the world, measuring 220km/140mi wide 🙂
We’re now going to give an overview of the most used technologies and tools for big data, some of the concepts and challenges behind it and a gentle introduction on how to start developing and testing big data applications in a virtualized environment.
For this article, we’ll focus mainly on data at rest applications and on the Hadoop ecosystem specifically.
Contents
Hadoop and big data platforms
![]()
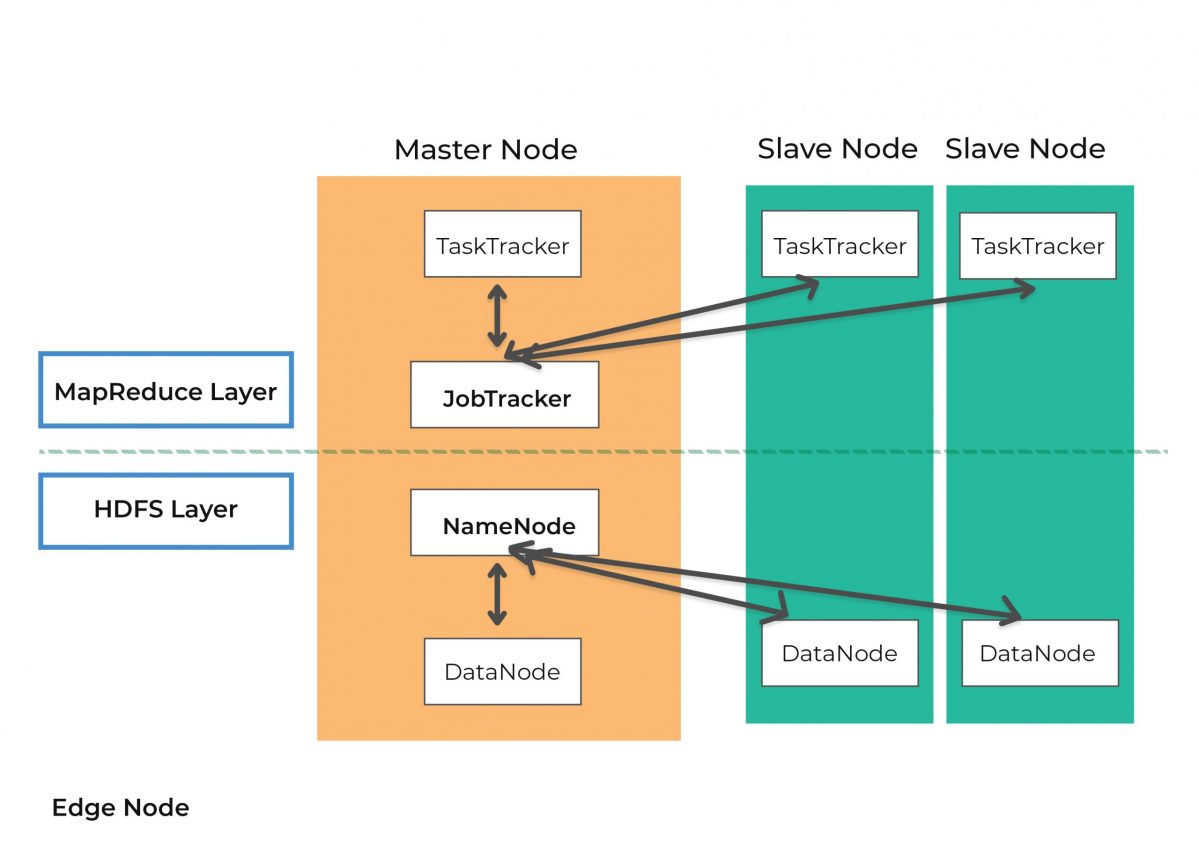
Hadoop is a framework developed by Apache used for the distributed processing of big data sets across multiple computers (called a cluster). At its core, Handoop uses the MapReduce programming model to process and generate a large amount of data. A MapReduce program consists of a Map procedure used to filter and/or sort the element of the dataset and a Reduce procedure which performs aggregations.
Other than providing a programming model suitable for distributed computing, Hadoop provides high availability as the data can be replicated easily across the node of the cluster. By default, Hadoop replicates the data three times.
A common Hadoop cluster is composed, at least, of the following components:
- An Edge Node or Gateway node
- A Name Node or Control/Master Node
- A Data Node or Worker Node
Edge Node
The purpose of the edge node is to provide access to the cluster, that’s why it’s also known as a gateway node. On the edge node, you can find the services needed to retrieve or transform data; some of those services are Impala, Hive, Spark, and Sqoop.
Name Node
Often called master node, the name node is used to store metadata of the Hadoop File System (HDFS) directory tree and all the files in the system. It doesn’t store the actual data, but it’s a sort of index for the distributed file system. The name node also executes the file system namespace operations like opening, closing, renaming, and deleting files and directories.
Data Node
As its name would suggest, the data node is where data is kept. Each node is responsible for serving read and write requests and performing data-block creation deletion and replication. Hadoop stores each file in block of data (default min size is 128MB).
References:
https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
Starting with Hadoop
Not everyone can afford a huge cluster, so how can you try Hadoop? Luckily, you can download and use the Cloudera quickstart Docker image that simulates a single node Hadoop “cluster”.
The following steps require you to have docker and docker-compose installed. If you don’t have them, follow the installation instructions for your OS here: https://docs.docker.com/install/.
Step 1
Download the image for the cloudera quickstart using the following command:
docker pull cloudera/quickstart
Step 2
Create a file called docker-compose.yml and add the following content:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
version: '2' services: cloudera: image: cloudera/quickstart:latest restart: always privileged: true hostname: quickstart.cloudera command: /usr/bin/docker-quickstart ports: - "8020:8020" # HDFS - "8022:22" # SSH - "7180:7180" # Cloudera Manager - "21050:21050" # Impala - "21000:21000" # Impala Thrift - "10001:10001" # Hive - "8888:8888" # Hue - "11000:11000" # Oozie - "50070:50070" # HDFS Rest Namenode - "50075:50075" # HDFS Rest Datanode - "2181:2181" # Zookeeper - "8088:8088" # YARN Resource Manager - "19888:19888" # MapReduce Job History - "50030:50030" # MapReduce Job Tracker - "8983:8983" # Solr - "16000:16000" # Sqoop Metastore - "8042:8042" # YARN Node Manager - "60010:60010" # HBase Master - "60030:60030" # HBase Region - "9090:9090" # HBase Thrift - "8081:8080" # HBase Rest - "7077:7077" # Spark Master tty: true stdin_open: true |
With this docker compose file, all the services are exposed, but you can decide which service you want to expose by simply removing the ports of the services you don’t need.
Step 3
Run the docker-compose file with the following command:
docker-compose up
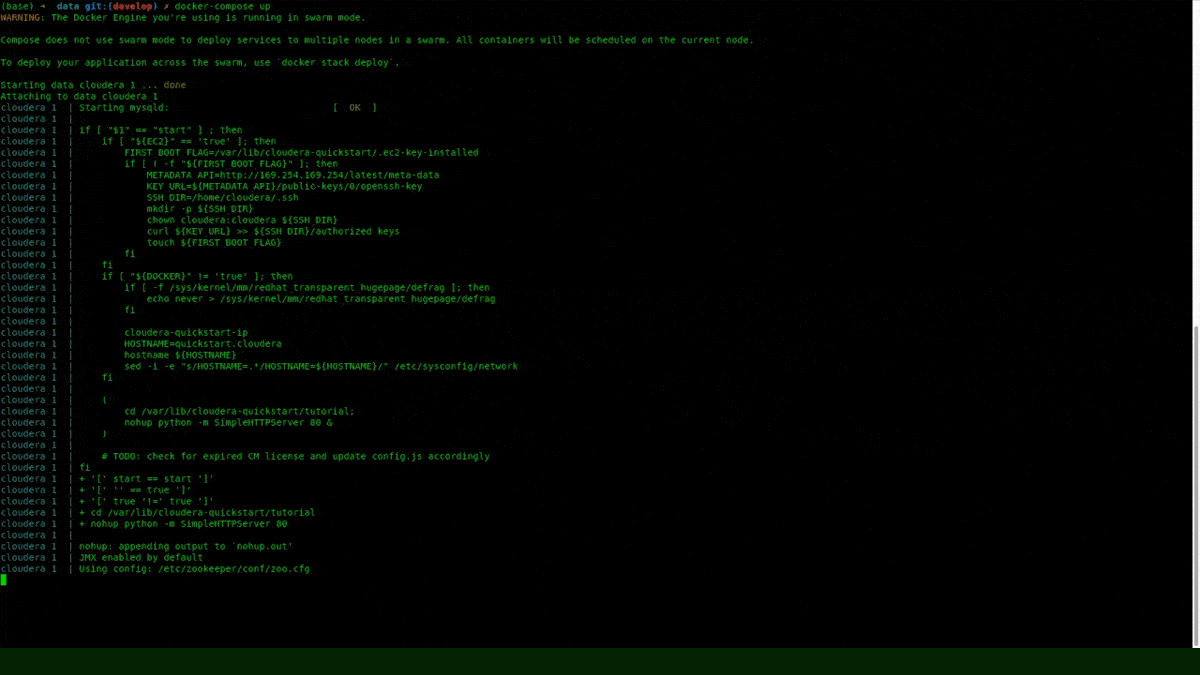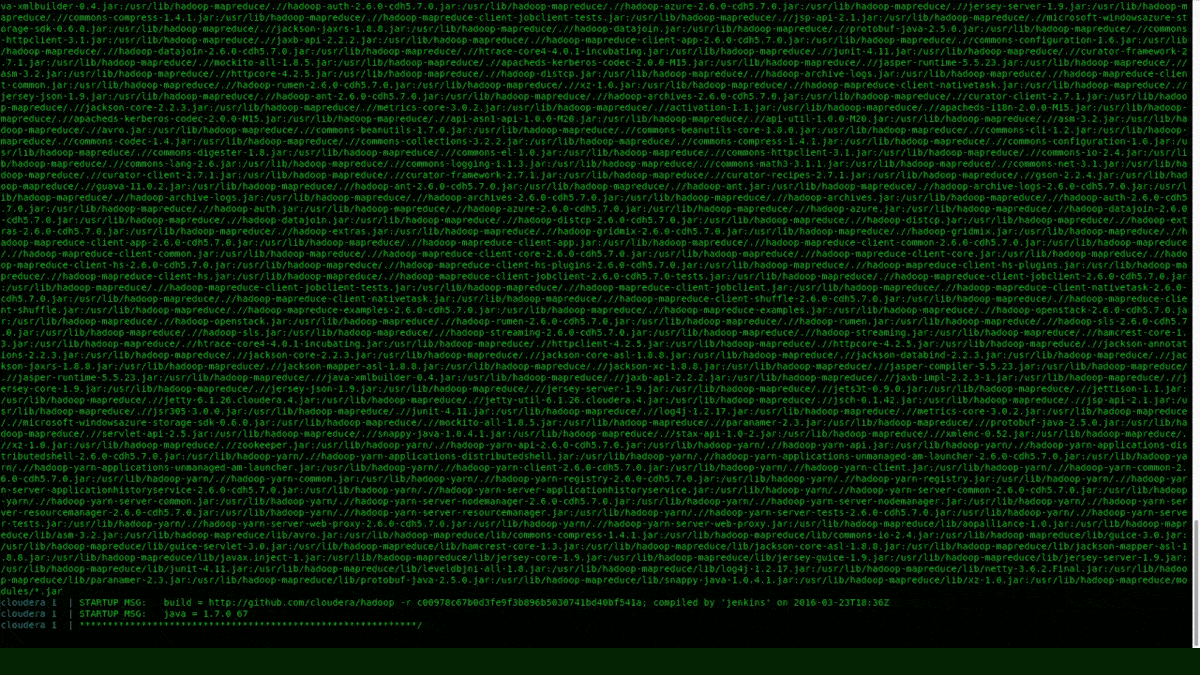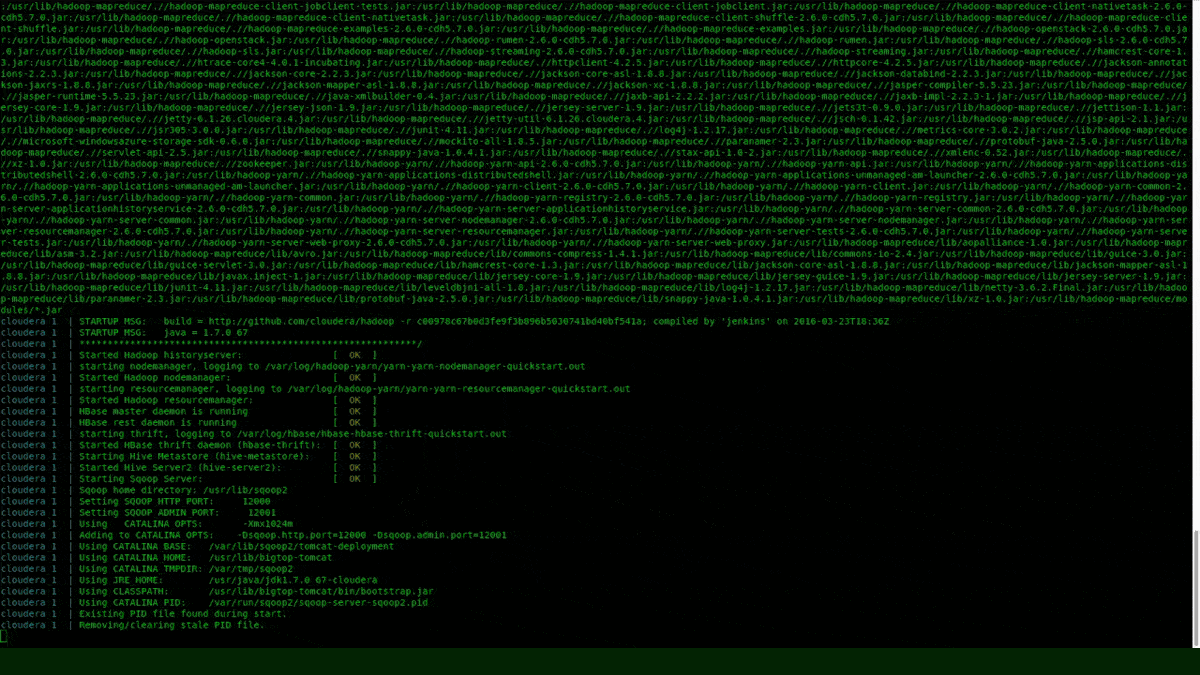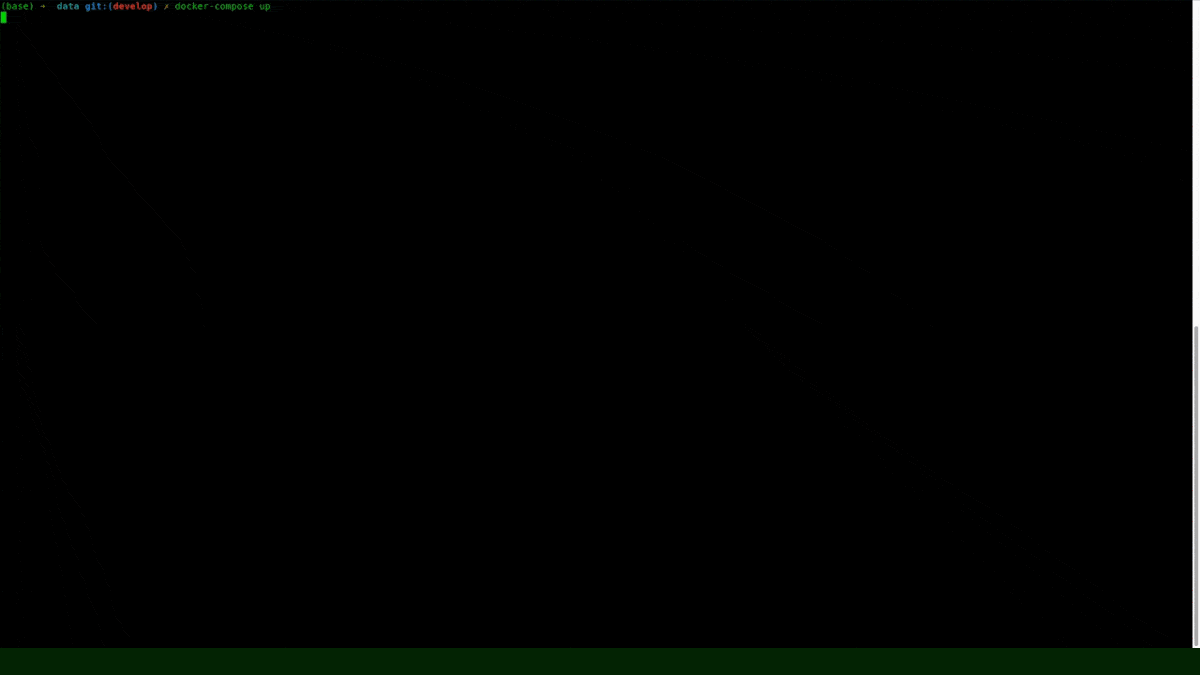
Step 4
At this point, you can start using the Hadoop environment.
Tools and Services of the Hadoop ecosystem
Impala

Impala is a service that allows you to create distributed databases over the Hadoop File System. By using it, it’s possible to query Hadoop as if it were a relational database server using SQL syntax.
As data in Hadoop are documents, data are stored in a similar way to NoSQL databases. By using Impala, you can have a relational layer (relations are stored in the metadata). That said, Impala and Hadoop are not ACID databases as they do not support transactions natively due to the CAP theorem and the distributed nature of Hadoop.
Hadoop, instead, satisfies the BASE type property of databases:
Basically
Available
Soft-state
Eventually-consistent
Note some functions may vary from MySQL/PostgreSQL or MsSQL specs.
To access the Impala service of the cloudera/quickstart image, click the following link: http://localhost:8888/impala
Here you can use the typical SQL commands to create databases and tables or query the existing databases. Impala exposes port 21000 which can be used to connect with a Thrift Connector and also port 21050 to connect via a JDBC Connector. The following are some code examples to show how you can connect your NodeJS or Python app to Impala.
Python
Install the impyla library with pip or conda
pip install
impyla
Create a file called app.py with the following content:
|
1 2 3 4 5 6 7 |
from impala.dbapi import connect conn = connect(host='localhost', port=21050) # setup the connection cursor = conn.cursor() # instantiate a cursor cursor.execute('SELECT 1+1') # execute a query print(cursor.description) # prints the result set's schema results = cursor.fetchall() print(results) # print the results |
Execute the file with the Python interpreter: python app.py
NodeJS
First, install the node-impala module:
npm i -s node-impala
Create a file called app.js with the following content:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
const { createClient } = require("node-impala"); const client = createClient(); // connect to the Impala thrift port 21000 client .connect({ host: "localhost", port: 21000, resultType: "json-array" }) .then(() => { // execute the query client .query("select 1+1") .then(console.log) }) .catch(error => console.error(error)); |
Execute the app.js file using Node interpreter: node app.js
Although there are libraries that connect Node with Impala, we can’t recommend Node for this task, as the available connectors do not support Kerberos authentication, something essential for a production environment. But, if you’re a developer who’s willing to invest time in learning how to interact with a distributed system, this could be a good start.
Loading data in Hadoop
We’ve shown how to connect to a simple Hadoop cluster, but how do you ingest data?
The Hadoop ecosystem provides some utilities that help you do that; one of them being Apache Sqoop. Using Sqoop, you can import data from any compatible jdbc database into Hadoop.
The following is an example of how to run a Sqoop import command:
|
1 2 3 4 5 6 7 8 |
sqoop \ import-all-tables \ --hive-import \ --create-hive-table \ --connect "jdbc:mysql://host_name/db_name" \ --username user \ --password secret \ -m 1 |
The command will import all the tables in the database, db_name, of the MySQL service running on localhost into a database called db_name in Impala.
Sometimes you just want to create a table from an exported file, like a CSV. In this case, you can use Python and the Ibis-framework library to do it in just six lines of code.
First, install the ibis-framework library using pip or conda:
pip install ibis-framework
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pandas as pd import ibis import re # create a connection with hdfs hdfs = ibis.hdfs_connect(host="localhost", port=50070) # create a connection with impala c = ibis.impala.connect(host="localhost", port=21050, hdfs_client=hdfs) # select the database db = c.database('default') # read a csv file data = pd.read_csv("./data/datasets/sales.csv") # remove whitespaces in column names data.columns = [re.sub(" ","_", col) for col in data.columns] # create and load csv file into a table called "sales" db.create_table('sales', data) |
Another way to load data into Hadoop is using the hdfs utilities. Basically, you can load the raw data using different file formats (csv, parquet, feather, avro, txt, images).
The following code demonstrates how to upload a file to hdfs using the python-hdfs library.
Install the library using the pip command:
pip install python-hdfs
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from hdfs import InsecureClient # connect to the webhdfs port 50070 web_hdfs_interface = InsecureClient('http://localhost:50070', user='cloudera') # upload the csv file in ./data/datasets/sales.csv to /user/cloudera/sales.csv web_hdfs_interface.upload( "/user/cloudera/sales.csv", "./data/datasets/sales.csv", overwrite=True) # list the files in /user/cloudera directory on hdfs files = web_hdfs_interface.list('/user/cloudera/') print(files) |
Using this method, Hadoop can also be used as a distributed and highly available file system.
Summary: a big data introduction
Everyday, big data is becoming more and more relevant as companies are generating and collecting huge amounts of data. As an example, here at UruIT, we’re developing a system for multinational telecom Telefonica/Movistar to find anomalies in its databases. The system is based on a combination of the described big data technologies plus some web technologies like NodeJS and React in order to link the two worlds (web and big data) together and provide an elegant user experience for both technical and non-technical users.
Moreover, big data helps in the development of Machine Learning and Deep Learning models, since having a large amount of data can increase the likelihood of finding hidden patterns. Taking our anomaly detection system as an example, once we collect enough data, we could introduce features such as error prediction in the system and autocorrection capabilities.
In this blog post, we’ve provided a brief introduction to the Hadoop ecosystem, showing how to set up and run a small instance of Hadoop using Cloudera quickstart docker image and how to connect to it in different ways and with programming languages.
This is just the tip of the big data “iceberg,” and we’ve only focused on big data at rest. When handling large volumes of data, other problems come into place, like partitioning data in the most performant way or reducing the amount of data shuffling between the nodes of the cluster to improve performance.
We have to say that setting up a Hadoop cluster on premise from scratch involves a lot of infrastructure work in order to physically provision the machines. To avoid this, you can rely on cloud services like Google DataProc and Amazon EMR where you can spin-up your cloud distributed cluster.
Please, leave us a comment letting us know your experience with big data and Hadoop and happy data munging!!! Also, feel free to contact us if you’d like to know more about our experience building big data apps. If you are interested in learning about big data and Machine Learning, we recommend the post in the link 🙂
