Contents
Microservices challenges and how it’s changing the way we make applications
The way to build software has changed over time; there are now many paradigms, languages, architectures and methodologies. Building applications based on microservices does not guarantee that the application will be a success (there’s no architecture nor methodology that guarantee that either), however it’s an approach that will teach you to manage your logical resources, components or modules. As a result, you can replicate them in different projects throughout your career, optimize resources and scale your applications in an agile way.
The beginning of my experience as a software developer was not easy; I had to change the paradigms I knew. I also had to read a lot, not only about technologies, but also about operating systems, volumes, and Unix sockets, among others things. In addition, I had to face challenges, and I am still facing them, because the implementations can be many, depending on the business requirements. This learning process didn’t just last a few weeks, but over a year and I’m still discovering new things! I had to learn to abstract a lot of business logic and divide it into reusable components, not only in one project, but also for use in other projects. Thinking about microservices definitely helped me to be a better programmer and take on new challenges, especially since the programming language takes a secondary role.
In this post, I want to give a brief introduction to microservices challenges and how it can be an alternative to software development.
We won’t focus on all the existing theory, such as design patterns, programming languages, frameworks, etc. Instead, this introduction will help us to understand many concepts (that we can go into more detail in future posts) about Backup as a Service (BaaS) and Disaster Recovery as a Service (DRaaS). If you want to explore more about microservices challenges, you can read the e-book, “Microservices from Design to Deployment,” published by NGINX; if you want to read about design patterns in microservices oriented architectures you can take a look at: https://microservices.io/
Lessons learned from Rome
In software development, as in politics, (and certainly in many aspects of life) the decisions we make while planning our project will affect its continuity in a positive or negative way. Divide and conquer or divide and rule, is a political concept born in Rome from its need to control cities after defeating one of its greatest rivals: the Latin League, a confederation of more than 30 tribes. The concept is quite simple, instead of attacking 30 nations at the same time, they devised an adoption system in which each of the tribes could adhere to the empire and obtain its benefits. Other tribes had autonomy, but over time, gradually the independent tribes began adhering. Without much effort, they were able to control a large portion of land and people without having to use force.
This is a great example not only of conciliation, but optimal resource management as well, because trying to control the tribes would have triggered riots, the dissolution of powers, and an increased investment in its military to contain them. If we apply this to the framework of the general theory of systems, what Rome did is to divide a great system into several microsystems, thus diluting the entropy that can affect the great system by reducing it.
Monolithic applications: a snowball
Generally, when we start a project, we use a code generator (such as SpringBoot, Cobuild, or Maven, among others) or simply clone a boilerplate, where the core of our application becomes the business logic implemented by modules that define services. Finally, around this, we create interfaces that serve as adapters for the outside.
Applications that implement this architecture are extremely common and easy to implement, test and deploy. You can also easily scale them by simply duplicating the application and running it behind a load balancer.
Unfortunately, this approach has a serious limitation: the complexity of implementation and deployment grows at the same rate as the application itself, just as a snowball would grow. I have seen this when I talk with other friends who have worked in traditional financial companies, where one of their main complaints is the difficulty of learning about a project. Typically, the installation of the development environment isn’t easy, so these applications take more than 10 minutes to compile and even start; imagine the effort required to make an emergency deployment! You could almost forget about your weekend if you have to deploy something on a Friday night. As you can see, it’s difficult to follow agile development in that type of project.
Monolithic applications are difficult to scale since many of their modules are competing for the system’s resources.
So, what is a microservice?
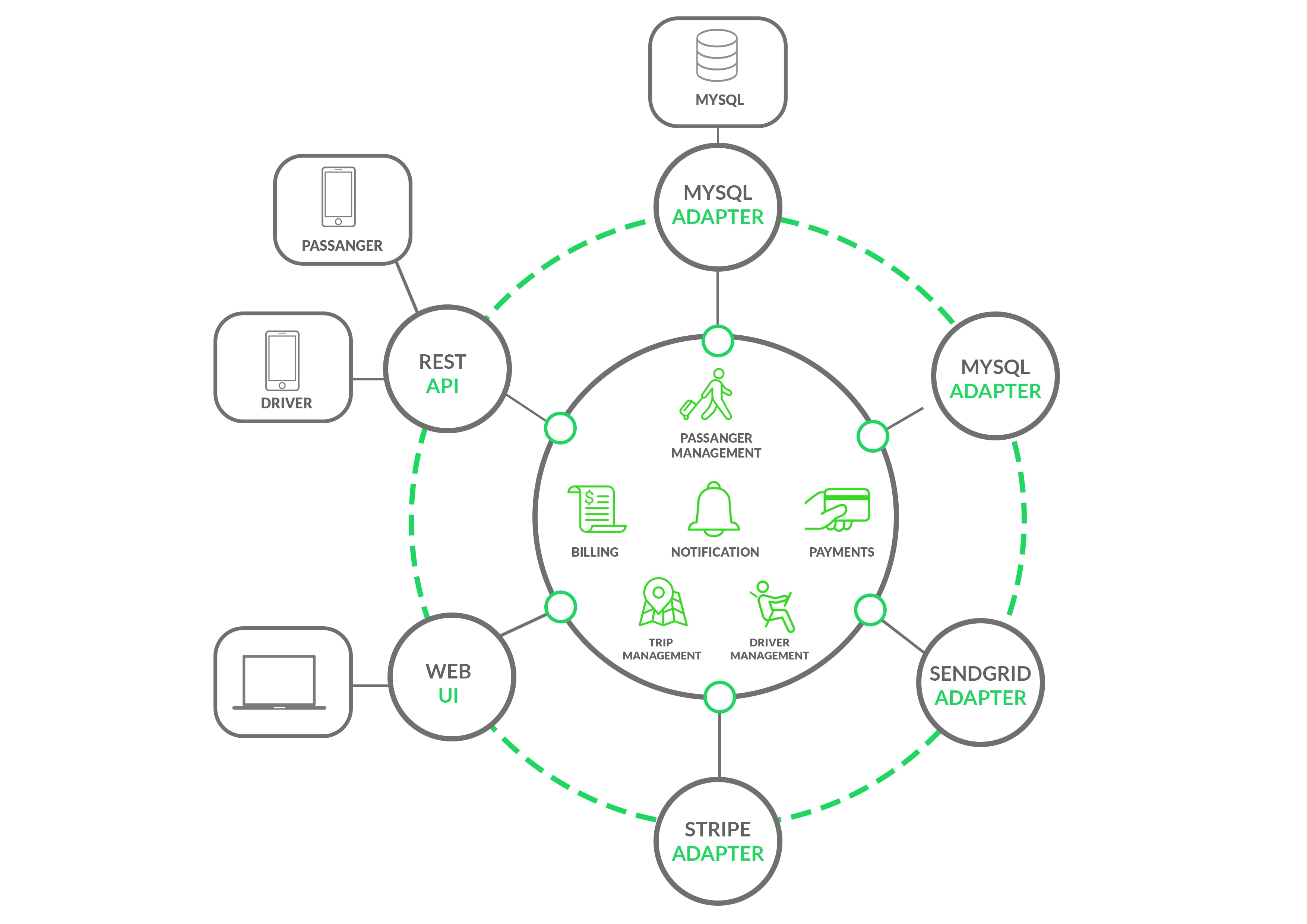
A microservice is an architecture in which each module, or piece of the application, is conceived as a unit; an isolated, separate service, but communicates—through network interfaces—with other isolated modules. Unlike monolithic applications, these microservices have their own scope, are independent and communicate with each other to obtain services, that is, a service requesting services. There are many technologies to implement them; Docker is the most famous along with Docker Compose and Kubernetes, which are dominating the container providers market. In this post, we will always talk about Docker, Docker Compose and Kubernetes. All these interactions and their set —that is, the sum of all these microservices— make the application work.
Unlike Image 1, Image 2 describes each module of the application implemented as a microservice. For example, if you need to make changes in the notification module, you would only have to deploy that specific microservice, independently of the other application components.
Microservices’ characteristics:
- Decentralization: the microservices are distributed through the system with decentralized data
- Independence: each microservice does not depend on another to operate
- The principle of single responsibility: each microservice has a function, and it must do it well
- Being a polyglot: it does not matter the language in which the microservice was written (Node, Python, Java or any desired programming language)
- Black box: microservices do not expose the complexity of their implementation
- Communication protocols: every microservice has its communication protocol with other microservices; this can be via sockets, http, grpc, etc.
The S.O.L.I.D (Single responsibility, Open-closed, Liskov substitution, Interface segregation and Dependency investment) principle is the theoretical concept behind microservices; but to execute it in practice poses many challenges.
Microservices Challenges
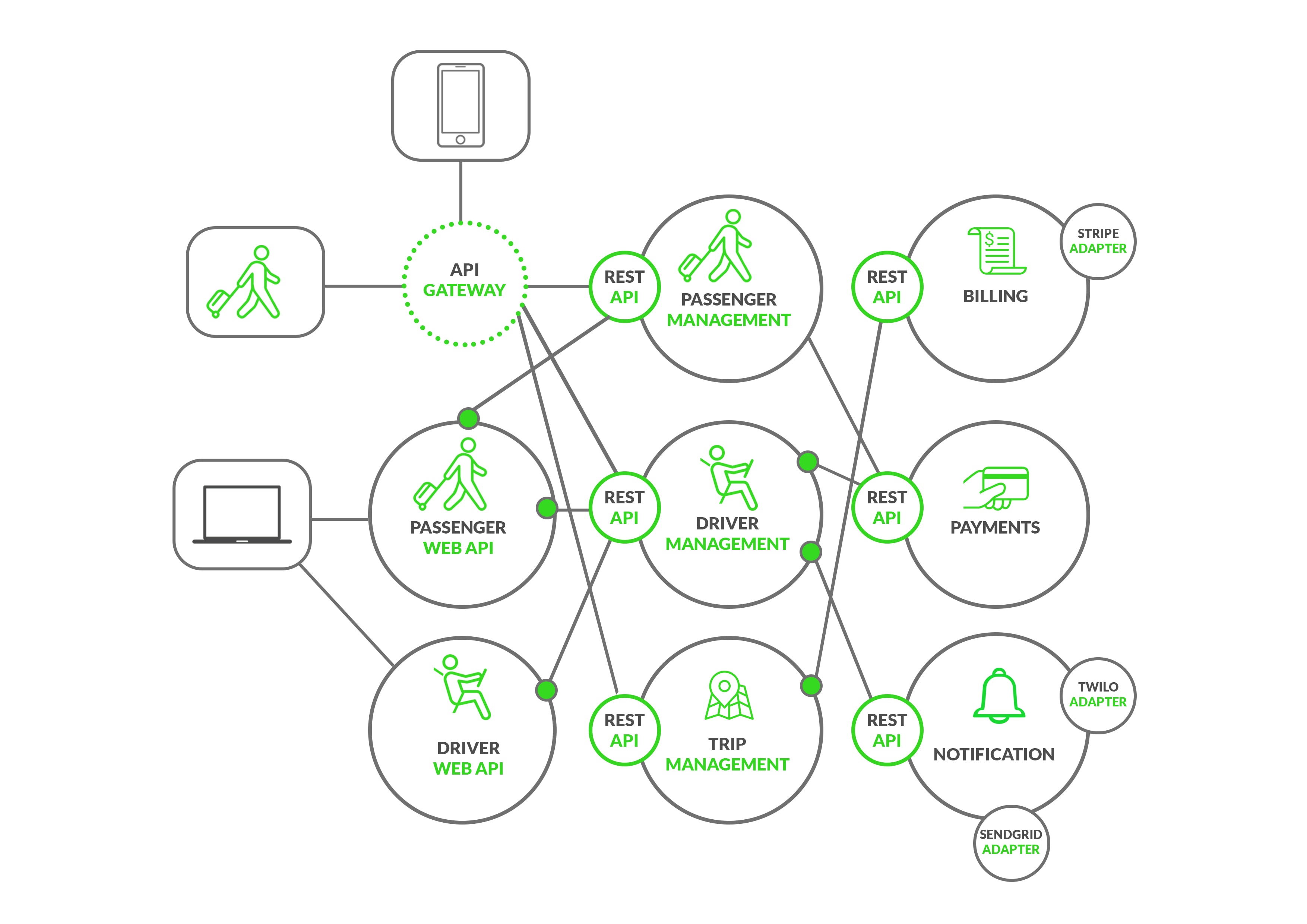
Although I had already worked with microservices in previous work experiences and in my personal projects, I faced a project which posed some difficulty. Even though I was told that the project was microservices-oriented, the dataflow and its implementation—perhaps due to a lack of knowledge of microservices’ characteristics or for convenience—ignored the responsibility of each microservice. This may sound like a problem but it’s not because the needs of the project should prevail over the theory. This is something common that happens in microservices projects; there is still no methodology for how to implement them successfully, nor is there a microservices market available where you can buy and reuse them in your projects to save time and money. In this project, each module was separated as its own microservice:
- The “cars” module was separated as a microservice.
- The “users” module was separated as a microservice.
- The “invoices” module was separated as a microservice.
- And, there was a gateway microservice. Theoretically, this microservice serves as the entry point for a client (web, mobile, iot, etc …); its responsibility is to redirect each request to the appropriate microservice.
Each microservice (except the gateway) had its own database.

What happens when two microservices share entities or relationships with other entities?
Normally, many of the models maintain a relationship with the “users” entity. In a monolithic application, each module shares its entities, since these are in the same directory (in the case of interpreted languages) or in the same memory space (in the case of compiled languages). In this particular case, they were in completely independent scopes, where these entities only know the interfaces that the other entities know.
To solve this problem, depending on the complexity, you could choose one of these approaches:
- A microservice for the database of your application and a database for exclusive use of your microservice.
- Using replicas, however, isn’t a good idea; the spatial cost would be very large, unless you need very high availability.
- Each microservice implementing an interface that allows other microservices to interact with it. Theoretically, this is good, however, we would be adding extra load to our microservices network. Although we would follow the theory literally, it’s not convenient if we want to use ORMs.
If the problem is to share code, you could consider separating the common code in libraries and storing them in repositories to be installed via Gitflow. Another common problem when developing microservices is failing to identify responsibilities properly. I have seen gateways that implement business logic and some cases where they make the monolithic application an entire microservice. This brings some inconveniences:
- What happens when 80% of the requests are directed to a small portion of this application? Resources are wasted.
- What happens if an event occurs and the heavy microservice stops responding? Two things might happen: raising this microservice will be expensive in terms of processing; if the lifetime periods are too short, you could replicate this heavy microservice. If you replicate it, you’re wasting even more resources.
Why should you try microservices?
The architecture of microservices brings several advantages. If you do it well, development will be less chaotic, deployment times will be shorter, a failure would not imply 0% availability, and you can integrate new features easily (scalability). In addition, you will be able to reuse them in most of your future projects. Last but not least, you will consume fewer resources in the cloud, meaning you’ll save money. You don’t have to believe me; instead, you could believe the authors of “Performance Evaluation of Microservices Architectures using Containers,” a project supported by IBM, where they concluded that:
Containers are gaining momentum because they offer lightweight OS virtualization capabilities. They are commonly used to host single processes in isolation on the system. While they offer clear advantages in terms of lightness and performance under several circumstances, they show limitations from the infrastructure management perspective. On the other hand, Server Virtualization has been widely adopted across sectors and industries because it provides simple mechanisms to manage the infrastructure, and group processes and applications. But it introduces several significant penalties in terms of deployment time, memory and processing overheads that vary with the nature of the applications that they host.
Reference: Performance Evaluation of Microservices
Architectures using Containers, link:https://core.ac.uk/download/pdf/81578653.pdf
This is so because, unlike the monolithic application, this app would run while being distributed in different threads. Besides, the operating system will be able to better dispense its resources according to the demand of each. Pay attention to this conversation of a monolithic application with the operating system:
At the moment of starting the monolithic application (MA)

Assuming that the application receives 500 requests per minute just for login, MA will be reserving memory for all application modules, no matter how much load they are receiving. In this conversation, perhaps the “users” module (assuming you’re using it for login) only occupies 80MB of RAM. The rest of the modules occupy 432 MB, and not only is RAM wasted, but also processing time. If you have handled a cloud provider, you’ll notice that this will cost money and no one likes to lose money.
In the case of microservices, the conversation would be a little different, it would have more voices; from the “users” microservice (UM), to the “cars” microservice (CM), the gateway microservice (GM), and finally a microservice for the database (DB).




The gateway will receive all the requests and will redirect them to the corresponding microservices. This means that the OS will allocate more resources for itself, while reducing the resources (mostly processing and memory exchange) for the microservices of low use. This means that there will be better system resource management. In terms of cloud, you will not have to pay so much for what you barely use… Now that starts to make some “cents”… Right?
How to implement microservices without dying from the attempt
Implementing microservices is not an easy task. However, if you properly define the responsibilities, the communication protocols and the data flows, it can be a success. Here are some basic tips for implementing it properly and overcoming common microservices challenges:
- Focus on making your microservice reusable regardless of the project. You could start building a gateway; without any business logic, (only the one you need to execute your task) which means, redirecting requests. In addition, the majority of applications will need authentication, access control or messaging services between them; you could use https://nats.io/ to broadcast messages from one microservice to another.
- There’s no need to be a purist; there is no rule to follow, so use what you need!
- Examine other microservices in public repositories. Github or Docker hub are good options, as there are people who are doing it really well.
- Use a container management platform for your microservices, for example, Kubernetes.
- Stop if you realize that you are adding responsibilities from one microservice to another that has nothing to do with it.
Final considerations about Microservices challenges
Microservices are expensive; you need to invest time and effort to build quality microservices. However, this opens the door to a world of possibilities. My experience with microservices at previous projects has left me with some great lessons, not only about software development, but also about networks, operating systems, and methodologies. Generally, companies, due to a lack of resources, cannot devote a team only to the development of these components. However, during the execution of our clients’ projects, we could (incrementally) start to create and refine our microservices. I developed microservices for pre-rendering pages in JavaScript, gateways, authentication, access control, SQLProxy of Gcloud, headless chrome, and bookstack for documentation. Also, I deployed Moodle as a microservice, and created a sandbox. I did not develop them overnight; on the contrary, we defined a thorough methodology for building them:
- Choose a project to start. Preferably a new project, which allows you to create the structure to your liking.
- Share the microservice with your colleagues.
- Your colleagues can then create tickets for missing functionalities. Also, they can even implement them on their own: they create a branch, test it, and generate the tests. Finally, a PR is made to the microservice.
- The team should make notification of the change and if there are side effects (there shouldn’t be any, or at least none that are critical). Do remember that the key to microservices is simplicity.
- The other developers who use the microservice decide whether to update or not.
If we can reuse NPM libraries, why couldn’t we reuse microservices or even sell them? We could have a microservice for functionalities such as:
- Gateway
- Authentication
- Access control
- Caching
- Mailing and notifications
- Pre-rendering
In upcoming posts, we will talk more about Disaster Recovery as a Service (DRaaS) and Backup as a Service (BaaS), but before reaching those subjects, I had to give an introduction to microservices challenges because we will need many of these concepts for future reference.
Thank you for reading!


1 comment